


Whenever you are trying to find " What is Git? " on the internet, then you find that " Git is a " Version Control System ". But Question is, What is Version Control System?
What is Version Control System?
It is a system that records changes to a file or set of files over time, so that we can recall specific versions later, i.e., for every source code change in a file a new version will be created.

Let us look at an example to see why we need git.
Consider an IT firm that develops software for clients. There are a lot of people who work in IT companies. To build faster, the software is divided into many features. Each employee creates features on their local system.
Scenario 1 - All of the features are developed by all developers, but what if, one of the employees' local systems becomes corrupt at the last minute?
Scenario 2 - All features are created by all developers (Version-1). Clint then wishes to change a few features (Version-2). You're attempting to create client requirements. But the code becomes buggy, and what if you have to revert to version-1?
Types of Version Control System
1 - Centralised Version Control System
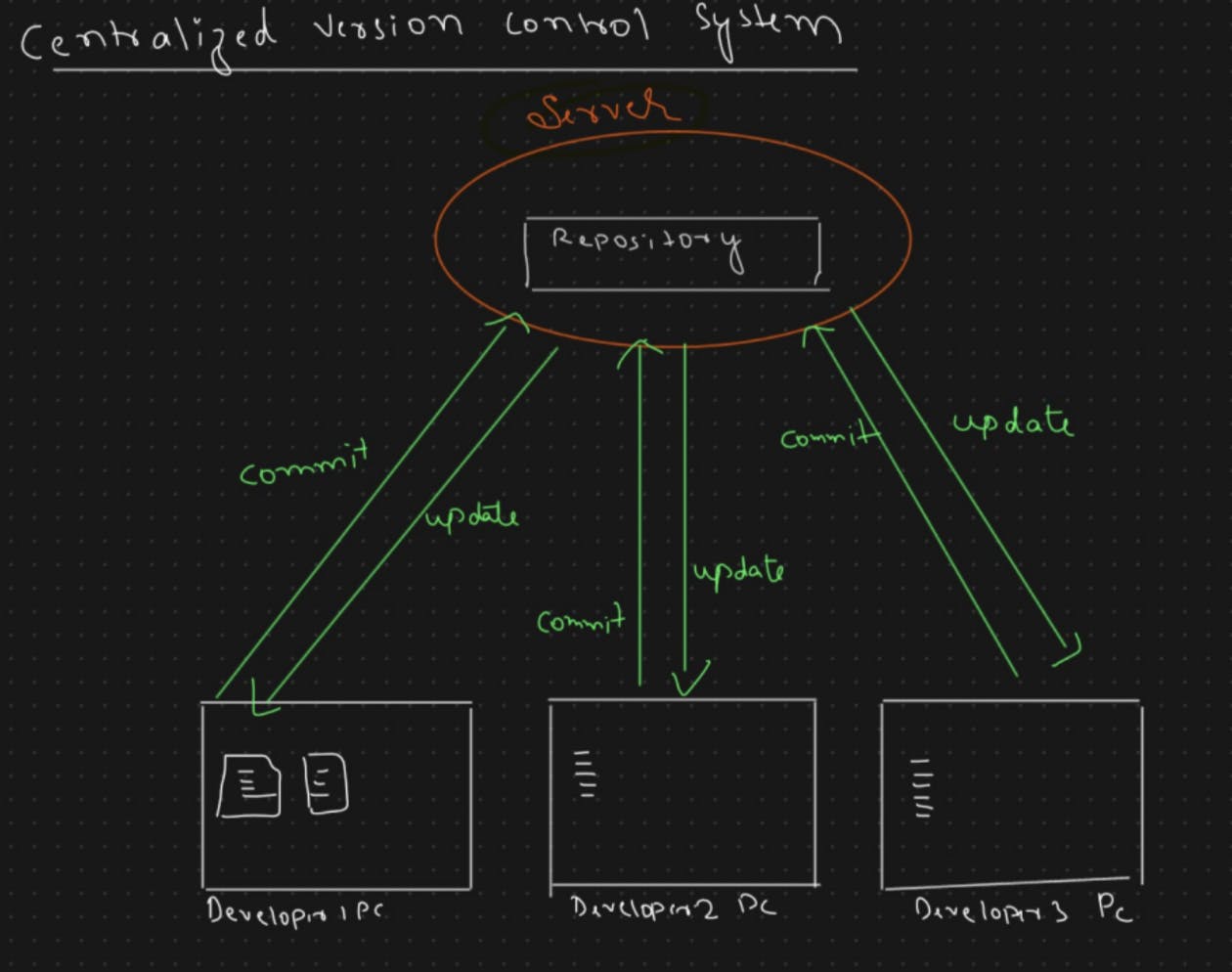
A centralised version control system (CVCS) is a type of version control system (VCS) in which all versions of a project's source code and associated files are stored in a single central repository. Developers typically check data from the central repository to work on them, make changes, and then check them back in. This allows for better team collaboration and ensures that everyone is working on the most recent version of the code.
One of the primary benefits of a CVCS is that it provides a single point of reference for the entire development team. When multiple developers are working on the same codebase, this makes it easier to manage changes and resolve conflicts. It also makes tracking changes over time and reverting to previous versions easier.
This solves both of our earlier scenarios, but it has one major drawback: the central repository can become a single point of failure. If the repository is lost or corrupted, recovering the most recent version of the code can be difficult or impossible. Furthermore, because all developers are working from the same central repository, working offline or on a slow or unreliable network connection can be more difficult. Finally, because all changes must be committed to the central repository, it can be challenging to test new ideas or make temporary changes without affecting the rest of the team.
2 - Distributed Version Control System
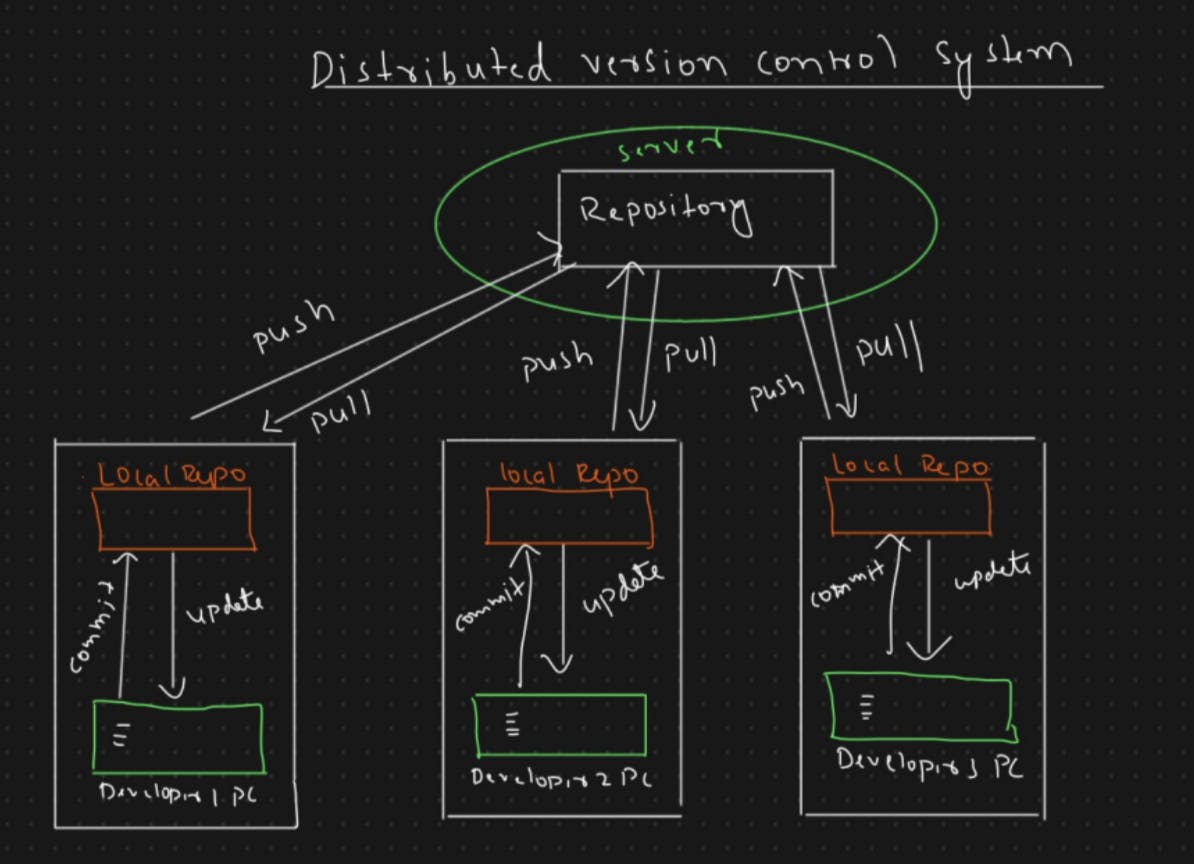
The main difference between a distributed version control system and a centralised version control system is that a layer of the repository is added to each developer's local system. A repository is a location or disc space where you can save all of your data.
Assume developer-1 writes some software code in this system. Developer-1 must first commit the code to his/her local repository. In this context, commit refers to saving data in his local repository. Developer-1 must then push the code to the remote repository. Everyone, including developer-2, developer-3, and so on, can now access the code from the remote repository by pulling the code from the remote repository. To pull means to bring code to our local repository (local system). Developers 2 and 3 can then access and update the code as well.
Important points to remember -
Developer-1 can not access the local repository of Developer-2, he/she can only access the main remote repository.
Once you pull the code from the main repository to your local system, then you don't need to have any Network connectivity until you want to push the code to the main remote repository.
Different Software for Distributed Version Control System
Git
Mercurial
Darcs
Bazaar & many more
Introduction of Git
We're talking about Git because it's the most popular version control system right now.
Git is a popular version control system(VCS). It was created by Linus Torvalds in 2005 and has been maintained by Junio Hamano.
Git is used for -
(a) Tracking code changes
(b) Tracking who made files like a history of the files
(c) Coading Collaboration
Git Software
There are 2 types of Git software
Git Server
Git Client
"When I do not know Git & GitHub, that time I thought that Git & GitHub both are same 😂."
However, Git and GitHub are not the same things. Git Server is what GitHub is. A main remote repository is Git Server. It is not required to use GitHub as the main remote repository. Git Servers such as Gitlab, BitBucket, GitBlit, and others are available. However, because GitHub is the most popular Git Server, in this case, we use it.
Git Client is open-source software. It is in the form of a .exe file. Here, .exe means executable file. Installing the Git Client on Windows is a simple task. We're talking about git Client Installation on Mac right now because I'm using one.
Git Client Installation
Method-1:- Install homebrew if you don't already have it, then:
$ brew install git
Method-2:- Install MacPorts if you don't already have it, then:
$ sudo port install git
Method-3:- If you want to use Git-GUI, then:
$ brew install git-gui
Git Architecture
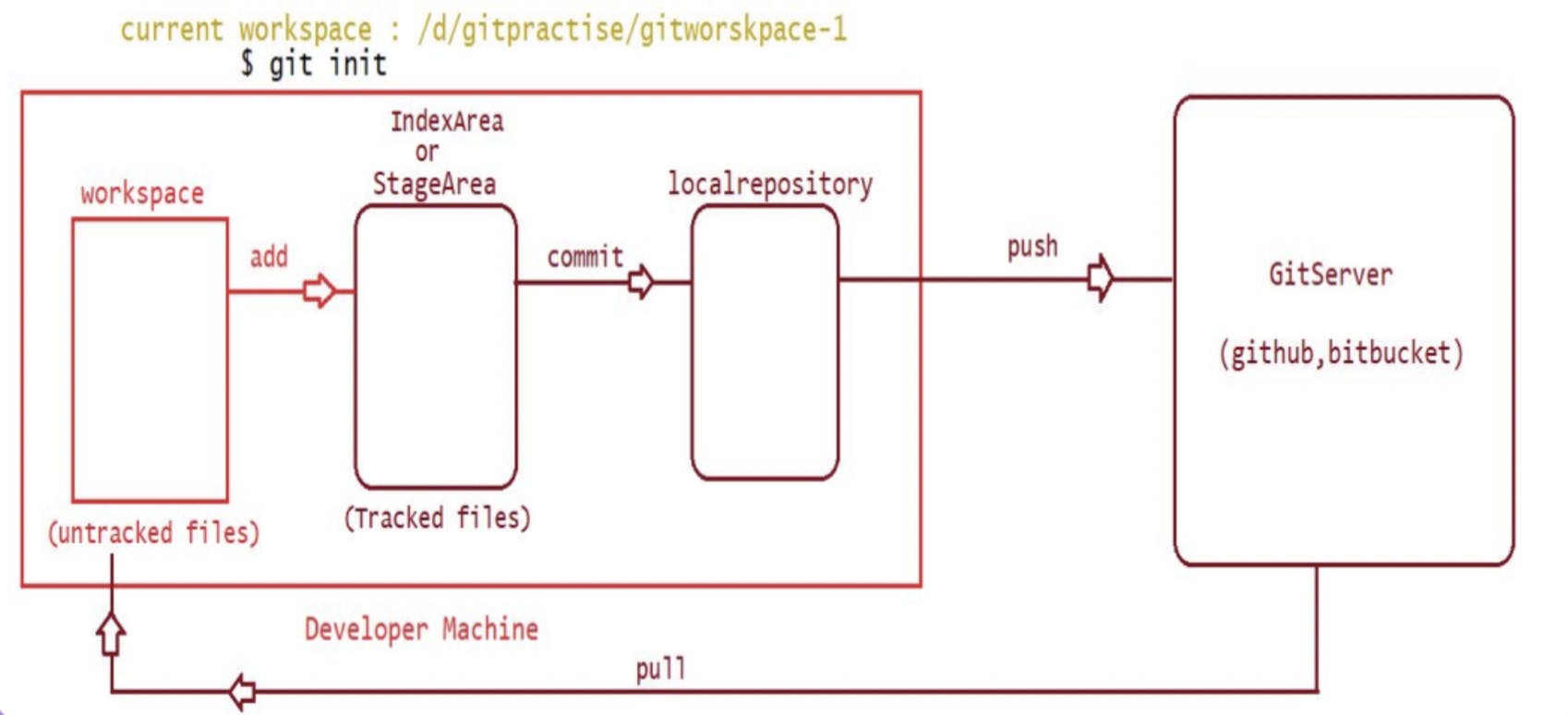
There are 3 stages involved :
Working area
Stage area
Local repository
In a working area, you write and develop your code. Developing code involves creating or editing files containing code. Once you have completed your work in the working area, you can add the files to the stage area. Before transferring code to the local repository, it must first be added to the stage area.
Once the files have been added to the stage area, the next step is to transfer the code to the local repository on our system. This transfer does not require a network connection since we are moving the code from our local working area to the local repository on our system.
Once the previous steps have been completed, the next task is to push the code to the main remote repository. The remote repository is essentially a storage location in the cloud. To complete this step, network connectivity is required as we are sending the data to the cloud.
Once the above process is completed, other developers who have access to the remote repository in the cloud can freely retrieve data by pulling it from the repository.
Now, we understand some Git commands. (In Part-II)